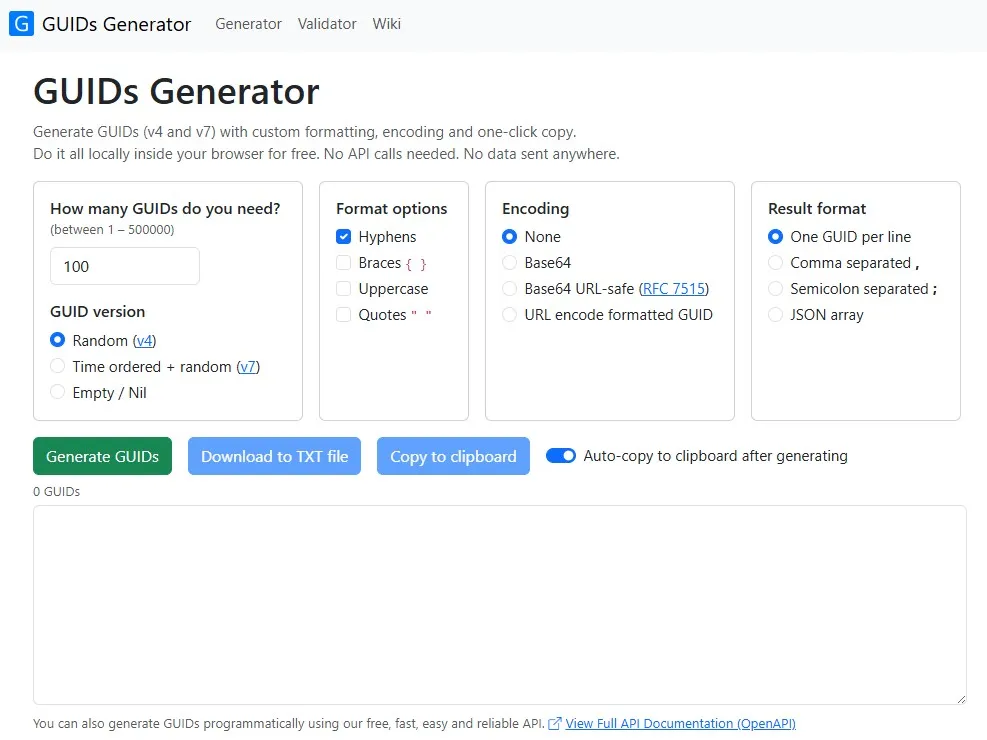
Pick Your Cut: A Chef's Guide to GUID Versions

Most developers know exactly one GUID / UUID version. They type Guid.NewGuid(), uuid.uuid4() or crypto.randomUUID(), get a random 128-bit value and move on. It works, so the question never comes up.
But the standard defines eight versions, plus a special nil value. Each one allocates the same 128 bits differently, and those choices change how the identifier sorts, what it leaks and where it belongs. Picking the right one is less like grabbing a random ingredient and more like choosing the right knife for the cut. Same kitchen, very different results.
Before you pick a cut, it helps to know how to read one. Then we will lay out all nine, from the 1997-era originals to the RFC 9562 additions that landed in 2024.
Know your cut: reading the version marker
Every GUID / UUID is 128 bits, written as 32 hex characters in the canonical 8-4-4-4-12 layout. The version lives in a single place: the first hex digit of the third group.
Canonical format: 8-4-4-4-12
Example: f47ac10b-58cc-4372-a567-0e02b2c3d479
Layout: xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
^ ^
| └─ N = Variant (layout family)
└────── M = Version (1-8)In that example the version is 4, so it is a GUID v4. The next group starts with the variant nibble a (binary 1010), which marks the standard RFC 4122 / RFC 9562 layout. For normal modern GUIDs / UUIDs that nibble is almost always 8, 9, a or b. Other values mean a legacy NCS or Microsoft layout you will rarely meet.
One hex character tells you how the identifier was generated. Another tells you which layout family it belongs to. Everything else is payload.
The tasting board: every version laid out
The versions sort into a few groups by intent, plus a couple of outliers:
- Time-based (v1, v6, v7) embed a timestamp so values carry creation order.
- Name-based (v3, v5) hash a namespace plus a name into a deterministic value.
- Random (v4) spends almost every bit on entropy.
- Custom (v8) hands the layout to you.
- Legacy (v2) is a deprecated relic you will never need.
- Nil/Empty is not really an identifier at all, just an all-zero placeholder.
Here is the side-by-side breakdown:
| Attribute | v1 | v2 | v3 | v4 | v5 | v6 | v7 | v8 | Nil/Empty |
|---|---|---|---|---|---|---|---|---|---|
| Type | Time + node (historically MAC) | DCE security (UID/GID) | Name (MD5) | Random | Name (SHA-1) | Reordered time v1 | Time-ordered + random | Custom / user-defined | All zeros |
| Deterministic | No | No | Yes | No | Yes | No | No | Depends | Yes |
| Sortable | Yes (~100 ns) | Partial | No | No | No | Yes (~100 ns) | Yes (millisecond) | Depends | N/A |
| Privacy | Leaks MAC | Leaks IDs | MD5 is broken | Safe | SHA-1 weakened | Safe | Safe | Custom | Not unique |
| Standard | RFC 4122 -> 9562 | RFC 4122 -> 9562 | RFC 4122 -> 9562 | RFC 4122 -> 9562 | RFC 4122 -> 9562 | RFC 9562 (2024) | RFC 9562 (2024) | RFC 9562 (2024) | RFC 4122 -> 9562 |
| Typical use | Distributed systems | Legacy DCE systems | Namespace-based IDs | General purpose (recommended) | Stable API IDs | Database indexing | Modern default | Experimental, app-specific | Sentinel / placeholder |
Scrape the plate: why v1 and v2 are done
v1 was the original design. It combines a 60-bit timestamp with a node identifier that was historically the machine’s MAC address. That gives you sortable, coordination-free IDs, but it also stamps the host’s hardware address into every value you hand out. For anything public, that is a privacy problem you do not want to ship.
v2 went further down the same road, embedding POSIX UID/GID alongside the MAC address for DCE security contexts. It is rarely implemented, effectively deprecated and safe to ignore in new work. If you ever meet a v2 in the wild, treat it as a fossil.
Both are sortable, and both pay for it by leaking host information. RFC 9562 discourages v1 and treats v2 as obsolete.
Cook it the same every time: v3 and v5
v3 and v5 solve a different problem. Instead of randomness, they hash a namespace and a name into a fixed value. Feed the same inputs and you always get the same GUID. That is exactly what you want when an identifier must be reproducible across systems without a shared lookup table.
The split between them is the hash function. v3 uses MD5, which is cryptographically broken. v5 uses SHA-1, which is weakened but holds up far better for this purpose. When you need deterministic IDs, reach for v5 and leave v3 alone.
Use this tier for stable API identifiers, content-addressed records or anything where the same input should always map to the same ID.
The kitchen staple: v4
v4 spends 122 of its 128 bits on cryptographically secure randomness. No timestamp, no host data, no order. Just entropy. That is why it became the default across nearly every language and framework after RFC 4122 shipped in 2005.
The math is comforting. 122 random bits give roughly 5.3 x 10^36 possible values, so collisions stay theoretical at any scale you will ever hit. v4 carries no metadata, which makes it the privacy-safe choice for tokens, public URLs and external identifiers.
The one thing it does not give you is order, and that is where the modern versions earn their place.
Modern plating: v6, v7 and v8
RFC 9562 arrived in May 2024 and added three versions aimed at problems v4 was never built to solve.
v6 is v1 with the timestamp bits reordered so the value sorts correctly as a plain string. It exists mainly as a migration path for systems already invested in v1 that want clean ordering without abandoning the format.
v7 is the one most teams should care about. It puts a 48-bit Unix-millisecond timestamp up front, then fills the remaining 74 bits with randomness. The result sorts by creation time, carries no host data and keeps the decentralized generation model of v4.
For database primary keys this matters: random v4 keys scatter inserts across a B-tree index and cause page splits, write amplification and fragmentation.
While time-ordered v7 keys cluster near the end of the index and behave much like an auto-increment integer. You also get rough chronological ordering for free, which often removes the need for a separate indexed created_at column.
v7 is not free. It leans on a reasonably accurate system clock, so a skewed or backward-moving clock can hand back out-of-order IDs. And because the timestamp is readable, v7 leaks creation time to anyone holding the value: fine for internal keys but worth a second thought for public ones.
v8 is the escape hatch. The spec reserves it for application-defined layouts, so you can pack your own data into the bits as long as you set the version and variant markers correctly. It is powerful and deliberately unopinionated. Use it only when you have a specific, well-understood reason. For everything else it is the wrong tool.
Off the menu entirely: empty/nil
The empty/nil GUID is all zeros: 00000000-0000-0000-0000-000000000000. It is not an identifier. It is a sentinel that means “no value”, the same way null does. Generate it never, compare against it often. Treating a nil as a real unique ID is a bug waiting to corrupt your data.
From pantry to plate: picking the right version
Strip away the history and the decision is short:
- New database keys, logs, event streams: v7. Ordering and index locality are real wins, and on a greenfield schema the cost is zero.
- Anything user-facing: v4. A v7 timestamp tells anyone holding the ID when it was created, and you can read that back out trivially. Keep timing metadata private.
- Reproducible IDs from the same input: v5. Deterministic, and safer than v3.
- Migrating an existing v1 system that needs ordering: v6. Same format, sortable output.
- A specialized layout you fully control: v8, and only then.
- Avoid: v1 and v2 for anything public, v3 for new work, nil as an actual identifier.
For a full breakdown of every version side by side, the complete GUID version comparison on GUIDsGenerator.com lays out the security and standards details in one table.
Make it a decision, not a reflex
Same 128 bits, a different cut for the job. You would not break down a fish with a bread knife, and you should not hand every system the same identifier by reflex.
Pick on purpose. The default is fine until the moment it quietly is not.
If you want the fastest, RFC-compliant, browser-based way to generate or inspect any of these guid versions, visit GUIDsGenerator.com.
Thank you for reading.
-Bruno